

《零基礎入門學習Python》筆記 第053講:論一隻爬蟲的自我修養
目錄
0. 請寫下這一節課你學習到的內容:格式不限,回憶並複述是加強記憶的好方式!
測試題
0. 請問URL 是“統一資源標識符”還是“統一資源定位符”?
1. 什麼是爬蟲?
2. 設想一下,如果你是負責開發百度蜘蛛的攻城獅,你在設計爬蟲時應該特別注意什麼問題?
3. 設想一下,如果你是網站的開發者,你應該如何禁止百度爬蟲訪問你網站中的敏感內容?
4. urllib.request.urlopen() 返回的是什麼類型的數據?
5. 如果訪問的網址不存在,會產生哪類異常?
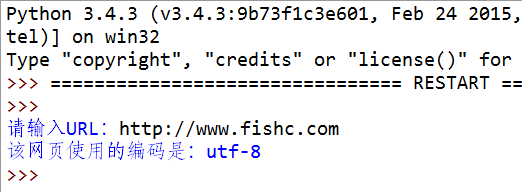
6. 魚C工作室(https://ilovefishc.com)的主頁採用什麼編碼傳輸的?
7. 為了解決ASCII 編碼的不足,什麼編碼應運而生?
動動手
0. 下載魚C工作室首頁(https://ilovefishc.com),並打印前三百個字節。
1. 寫一個程序,檢測指定URL 的編碼。
2. 寫一個程序,依次訪問文件中指定的站點,並將每個站點返回的內容依次存放到不同的文件中。
0. 請寫下這一節課你學習到的內容:格式不限,回憶並複述是加強記憶的好方式!
馬上我們的教學就要進入最後一個章節,Pygame 嗨爆引爆全場,但由於發生了一個小插曲,所以這裡決定追加一個章節,因為有人反應說:“你上一節課教我們去查找文檔,教我們如何從官方文檔中找到需要的答案,但是我發現知易行難也,希望舉一個詳細點的例子,教我們如何去查找。”
所以這裡我們詳細的深刻的講一下網絡爬蟲。所以就有了本章節,論一隻爬蟲的自我修養。
首先,我們需要理解,什麼是網絡爬蟲,如圖:
 網絡爬蟲又稱為網絡蜘蛛(Spider),如果你把整個互聯網想像為一個蜘蛛網的構造,每個網站或域名都是一個節點,那我們這只蜘蛛就是在上面爬來爬去,在不同的網頁上爬來爬去,順便獲得我們需要的資源,抓取最有用的。做過網站的朋友一定很熟悉,我們之所以能夠通過百度、谷歌這樣的搜索引擎檢索到你的網頁,靠的就是他們每天派出大量的蜘蛛在互聯網上爬來爬去,對網頁中的每個關鍵字建立索引,然後建立索引數據庫,經過了複雜的排序算法之後,這些結果將按照搜索關鍵詞的相關度的高低展現在我們的眼前。那當然,現在讓你編寫一個搜索引擎是一件非常苦難的、不可能完成的事情,但是有一句老話說的好啊:千里之行,始於足下。我們先從編寫一段小爬蟲代碼開始,然後不斷地來改進它,要使用Python編寫爬蟲代碼,我們要解決的第一個問題是:
Python如何訪問互聯網?
好在Python為此準備好了電池,Python為此準備的電池叫做:urllib
網絡爬蟲又稱為網絡蜘蛛(Spider),如果你把整個互聯網想像為一個蜘蛛網的構造,每個網站或域名都是一個節點,那我們這只蜘蛛就是在上面爬來爬去,在不同的網頁上爬來爬去,順便獲得我們需要的資源,抓取最有用的。做過網站的朋友一定很熟悉,我們之所以能夠通過百度、谷歌這樣的搜索引擎檢索到你的網頁,靠的就是他們每天派出大量的蜘蛛在互聯網上爬來爬去,對網頁中的每個關鍵字建立索引,然後建立索引數據庫,經過了複雜的排序算法之後,這些結果將按照搜索關鍵詞的相關度的高低展現在我們的眼前。那當然,現在讓你編寫一個搜索引擎是一件非常苦難的、不可能完成的事情,但是有一句老話說的好啊:千里之行,始於足下。我們先從編寫一段小爬蟲代碼開始,然後不斷地來改進它,要使用Python編寫爬蟲代碼,我們要解決的第一個問題是:
Python如何訪問互聯網?
好在Python為此準備好了電池,Python為此準備的電池叫做:urllib
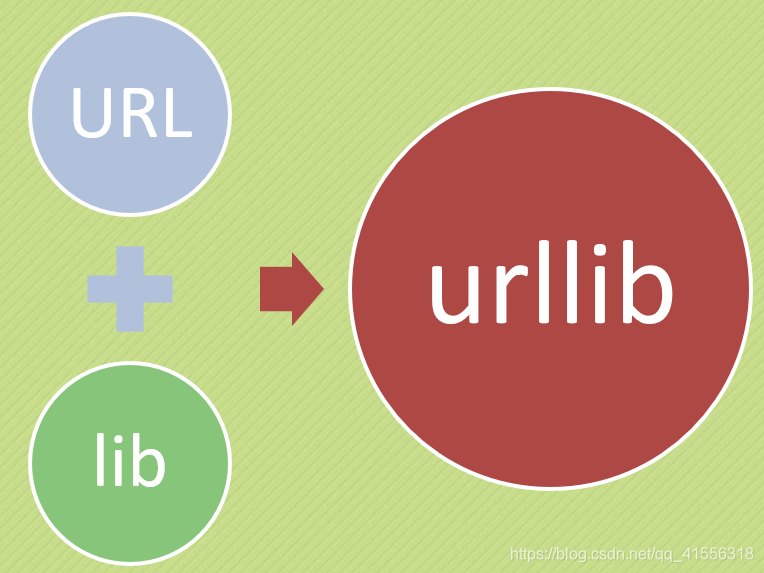 urllib 事實上是由兩個單詞組成的:URL(就是我們平時說的網頁地址) 和lib(就是library的意思,就是首頁)。
urllib 事實上是由兩個單詞組成的:URL(就是我們平時說的網頁地址) 和lib(就是library的意思,就是首頁)。
•URL的一般格式為(帶方括號[]的為可選項):
protocol :// hostname[:port] / path / [;parameters][?query]#fragment
•URL由三部分組成:
–第一部分是協議(protocol):http,https,ftp,file,ed2k…
–第二部分是存放資源的服務器的域名系統或IP地址(有時候要包含端口號,各種傳輸協議都有默認的端口號,如http的默認端口為80)。
–第三部分是資源的具體地址,如目錄或文件名等。
那好,說完URL,我們現在可以來談一下urllib 這個模塊了,Python 3 其實對這個模塊進行了挺大的改動,以前有urllib和urllib2 兩個模塊,Python3 乾脆把它們合併在了一起並做了統一。其實urllib 並不是一個模塊,而是一個包。我們來查一下文檔就知道了(我們說過,有問題,找文檔。)
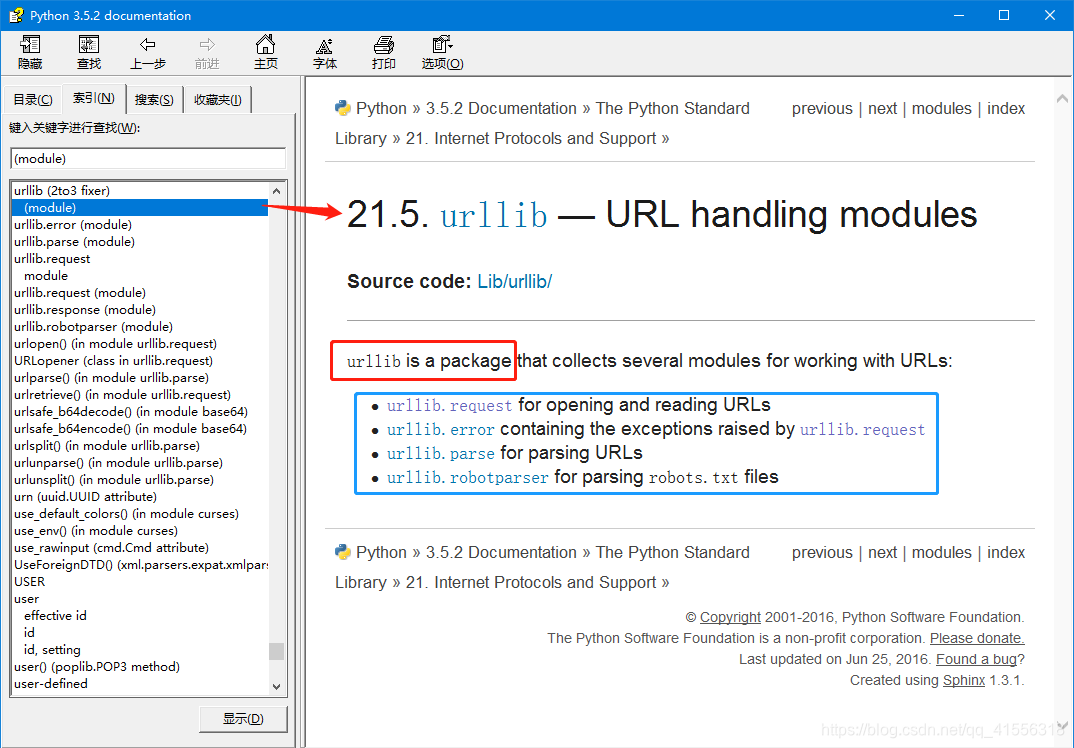 urllib 其實是一個包,其中包含4個模塊,request 、error、parse 和robotparser,我們主要會來講解request 這個模塊,這個模塊也是最複雜的,因為它包含了對服務器的請求和發出、跳轉、代理、安全等幾大方面。
我們點進去會發現文檔非常長,從頭看到尾是不可能的,這時候怎麼辦呢?建議百度、谷歌,查詢urllib.request 的用法,或者查詢Python3 如何訪問網頁,也可以得到想要的結果。你會得到,使用urlopen() 這個函數。
urllib 其實是一個包,其中包含4個模塊,request 、error、parse 和robotparser,我們主要會來講解request 這個模塊,這個模塊也是最複雜的,因為它包含了對服務器的請求和發出、跳轉、代理、安全等幾大方面。
我們點進去會發現文檔非常長,從頭看到尾是不可能的,這時候怎麼辦呢?建議百度、谷歌,查詢urllib.request 的用法,或者查詢Python3 如何訪問網頁,也可以得到想要的結果。你會得到,使用urlopen() 這個函數。
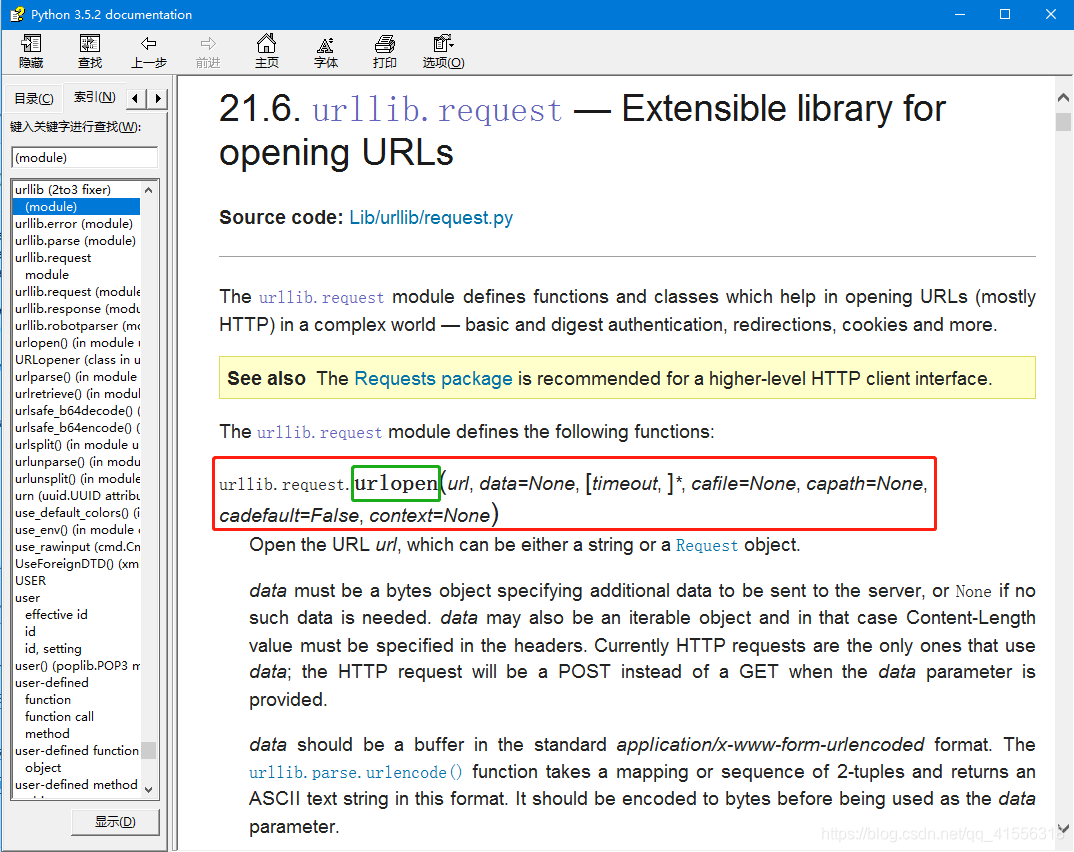 urlopen()函數除了第一個參數url是必需的外,後面的都有默認參數和可選參數,文檔告訴我們,url可以是一個字符串或者Request object。Request object是什麼,我們下節課講解。我們猜測url為一個字符串是應該就是域名地址的字符串,我們先來嘗個鮮:(之所以選擇https://ilovefishc.com這個網頁,是因為這個網頁的源代碼量較少,其他的網站會直接把IELD搞崩潰,不信你可以試試https://www.baidu.com。)
urlopen()函數除了第一個參數url是必需的外,後面的都有默認參數和可選參數,文檔告訴我們,url可以是一個字符串或者Request object。Request object是什麼,我們下節課講解。我們猜測url為一個字符串是應該就是域名地址的字符串,我們先來嘗個鮮:(之所以選擇https://ilovefishc.com這個網頁,是因為這個網頁的源代碼量較少,其他的網站會直接把IELD搞崩潰,不信你可以試試https://www.baidu.com。)
 我們會發現網頁的代碼很整齊,那這是怎麼回事呢?為什麼Python這里高的一團糟,我們剛才說了,Python這裡直接得到的是byte類型(二進制編碼),所以我們可以對它進行解碼操作,我們先來看一下這個網頁的編碼方式是:UTF-8。
我們會發現網頁的代碼很整齊,那這是怎麼回事呢?為什麼Python這里高的一團糟,我們剛才說了,Python這裡直接得到的是byte類型(二進制編碼),所以我們可以對它進行解碼操作,我們先來看一下這個網頁的編碼方式是:UTF-8。
•URL的一般格式為(帶方括號[]的為可選項):
protocol :// hostname[:port] / path / [;parameters][?query]#fragment
•URL由三部分組成:
–第一部分是協議(protocol):http,https,ftp,file,ed2k…
–第二部分是存放資源的服務器的域名系統或IP地址(有時候要包含端口號,各種傳輸協議都有默認的端口號,如http的默認端口為80)。
–第三部分是資源的具體地址,如目錄或文件名等。
測試題
0. 請問URL 是“統一資源標識符”還是“統一資源定位符”?
答:往後的學習你可能會經常接觸URL 和URI,為了防止你突然懵倒,所以在這裡給大家簡單普及下。URI 是統一資源標識符(Universal Resource Identifier),URL 是統一資源定位符(Universal Resource Locator)。用一句話概括它們的區別:URI 是用字符串來標識某一互聯網資源,而URL 則是表示資源的地址(我們說某個網站的網址就是URL),因此URI 屬於父類,而URL 屬於URI的子類。
1. 什麼是爬蟲?
答:爬蟲事實上就是一個程序,用於沿著互聯網結點爬行,不斷訪問不同的網站,以便獲取它所需要的資源。
2. 設想一下,如果你是負責開發百度蜘蛛的攻城獅,你在設計爬蟲時應該特別注意什麼問題?
答:不要重複爬取同一個URL 的內容。假設你沒做這方面的預防,如果一個URL 的內容中包含該URL 本身,那麼就會陷入無限遞歸。
3. 設想一下,如果你是網站的開發者,你應該如何禁止百度爬蟲訪問你網站中的敏感內容?
(課堂上沒講,可以自行百度答案)
答:在網站的根目錄下創建並編輯robots.txt 文件,用於表明您不希望搜索引擎抓取工具訪問您網站上的哪些內容。此文件使用的是Robots 排除標準,該標準是一項協議,所有正規搜索引擎的蜘蛛均會遵循該協議爬取。既然是協議,那就是需要大家自覺尊重,所以該協議一般對非法爬蟲無效。
4. urllib.request.urlopen() 返回的是什麼類型的數據?
答:返回的是一個HTTPResponse的實例對象,它屬於http.client模塊。
5. 如果訪問的網址不存在,會產生哪類異常?
(雖然課堂沒講過,但你可以動手試試)
答:HTTPError
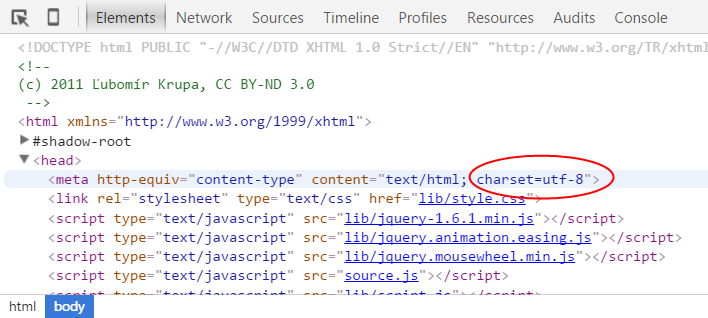
6.魚C工作室(https://ilovefishc.com )的主頁採用什麼編碼傳輸的?
答:UTF-8 編碼。
一般網頁通過點擊審查元素,在<head> 標籤中的charset 會顯示採用了哪種編碼。
7. 為了解決ASCII 編碼的不足,什麼編碼應運而生?
答:Unicode編碼。擴展閱讀關於編碼的那篇文章太長了,有魚油說太生澀難懂,對於對編碼問題還一頭霧水的魚油請看-> 什麼是編碼?
動動手
0.下載魚C工作室首頁(https://ilovefishc.com ),並打印前三百個字節。
代碼清單:
1. 寫一個程序,檢測指定URL 的編碼。
演示:
 提示:
提供個“電池”給你用-> 一次性解決你所有的編碼檢測問題
代碼清單:
提示:
提供個“電池”給你用-> 一次性解決你所有的編碼檢測問題
代碼清單:
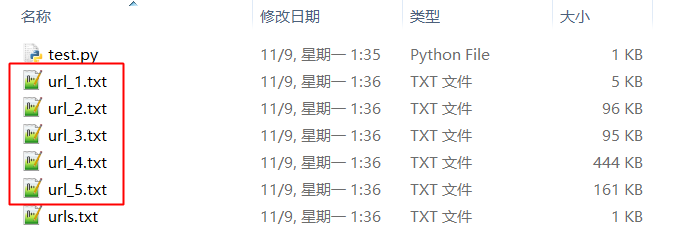
2. 寫一個程序,依次訪問文件中指定的站點,並將每個站點返回的內容依次存放到不同的文件中。
演示:
urls.txt 文件存放需要訪問的ULR:
 執行你寫的程序(test.py),依次訪問指定的URL 並將其內容存放為一個新的文件:
執行你寫的程序(test.py),依次訪問指定的URL 並將其內容存放為一個新的文件:
 代碼清單:
代碼清單:




0 留言:
發佈留言