

《零基礎入門學習Python》筆記 第054講:論一隻爬蟲的自我修養2:實戰
目錄
0. 請寫下這一節課你學習到的內容:格式不限,回憶並複述是加強記憶的好方式!
測試題
0. urlopen() 方法的timeout 參數用於設置什麼?
1. 如何從urlopen() 返回的對像中獲取HTTP 狀態碼?
2. 在客戶端和服務器之間進行請求-響應時,最常用的是哪兩種方法?
3. HTTP 是基於請求-響應的模式,那是客戶端發出請求,服務端做出響應;還是服務端發出請求,客戶端做出響應呢?
4. User-Agent 屬性通常是記錄什麼信息?
5. 如何通過urlopen() 使用POST 方法像服務端發出請求?
6. 使用字符串的什麼方法將其它編碼轉換為Unicode 編碼?
7. JSON 是什麼鬼?
動動手
0. 配合EasyGui,給“下載一隻貓“的代碼增加互動:
1. 寫一個登錄豆瓣的客戶端。
0. 請寫下這一節課你學習到的內容:格式不限,回憶並複述是加強記憶的好方式!
今天我們決定在實戰中來進行學習,會舉兩個例子,第一個例子是我們會下載一隻貓,第二個例子是我們用Python來模擬瀏覽器通過在線的谷歌翻譯進行文本的翻譯。
如果你認為上節課我只是簡單介紹了一下urlopen() 函數的用法,那你就錯了,上節課我已經說了,相關的文檔在哪裡,要教你的東西在文檔裡都有, OK,我們來第一個例子吧。
(一)使用Python下載一隻貓
我們常說,林子大了,什麼鳥都有。互聯網這麼大,那當然不管什麼樣的奇葩網站都會有。我們今天舉的例子就是要訪問一個http://placekitten.com/,這個網站是為貓農量身定制的一個站點,網站後面你只需要加上/寬度/高度,就可以得到一隻相應寬度和高度的貓的圖片。這些圖片都是JPG格式的,你可以通過右鍵將其簡單保存到桌面上。
我們第一個例子就是使用Python實現剛才的操作,事實上我們上節課教過的內容也是完全足夠的,我們新建一個download_cat.py 文件。
首先,我們需要import urllib.request,然後使用urlopen()函數得到response,得到的cat_img可以用一個文件保存,我們命名這個文件為cat_500_600.jpg,我們說過,圖片也是文件,它也是二進制數據組成的,我們這裡用'wb'將收到的二進制數據寫入jpg格式的文件就可以了。
response = urllib.request.urlopen("http://placekitten.com/500/600")
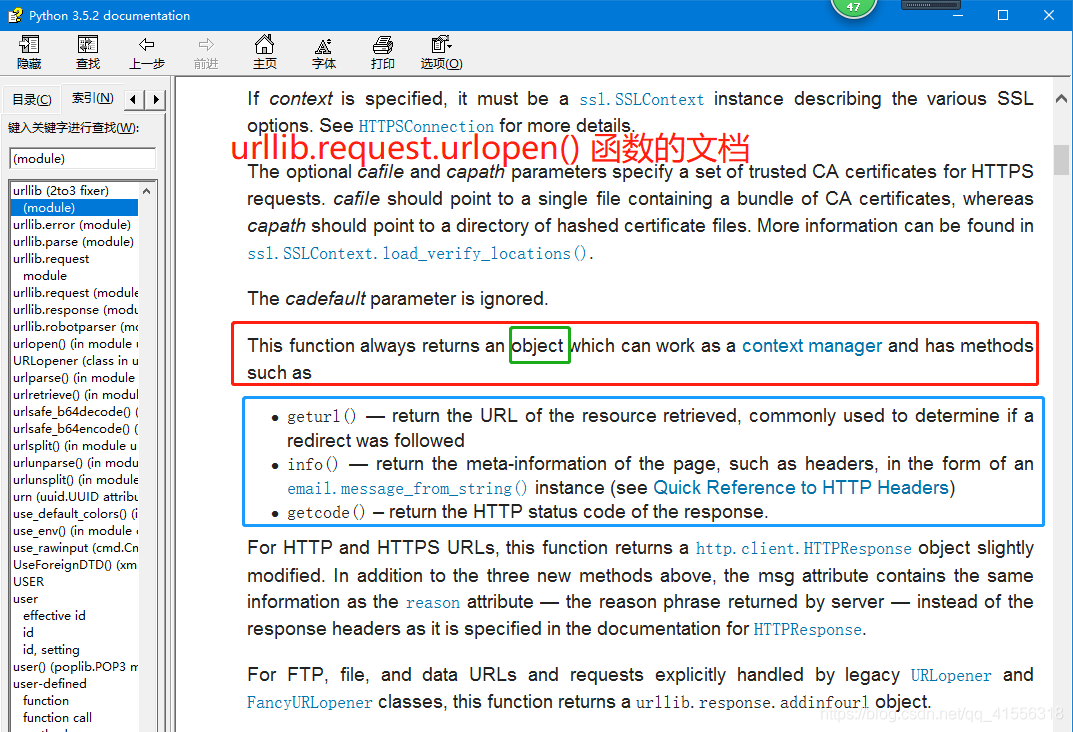 文檔還告訴我們,除了可以使用read() 方法之外,還可以是使用geturl() 、info() 和getcode() 方法,我們試一下這三個函數分別返回什麼:
我們運行 download_cat.py 之後,調用這幾個方法:
文檔還告訴我們,除了可以使用read() 方法之外,還可以是使用geturl() 、info() 和getcode() 方法,我們試一下這三個函數分別返回什麼:
我們運行 download_cat.py 之後,調用這幾個方法:
 我們怎樣編寫Python 程序模擬瀏覽器,讓它翻譯呢?我們首先要介紹的是審查元素這個功能。基本上現在所有的瀏覽器都會自帶這樣這個調試插件,以360瀏覽器為例,右鍵選擇-審查元素,或者直接按F12,就會顯示審查元素窗口。
我們怎樣編寫Python 程序模擬瀏覽器,讓它翻譯呢?我們首先要介紹的是審查元素這個功能。基本上現在所有的瀏覽器都會自帶這樣這個調試插件,以360瀏覽器為例,右鍵選擇-審查元素,或者直接按F12,就會顯示審查元素窗口。
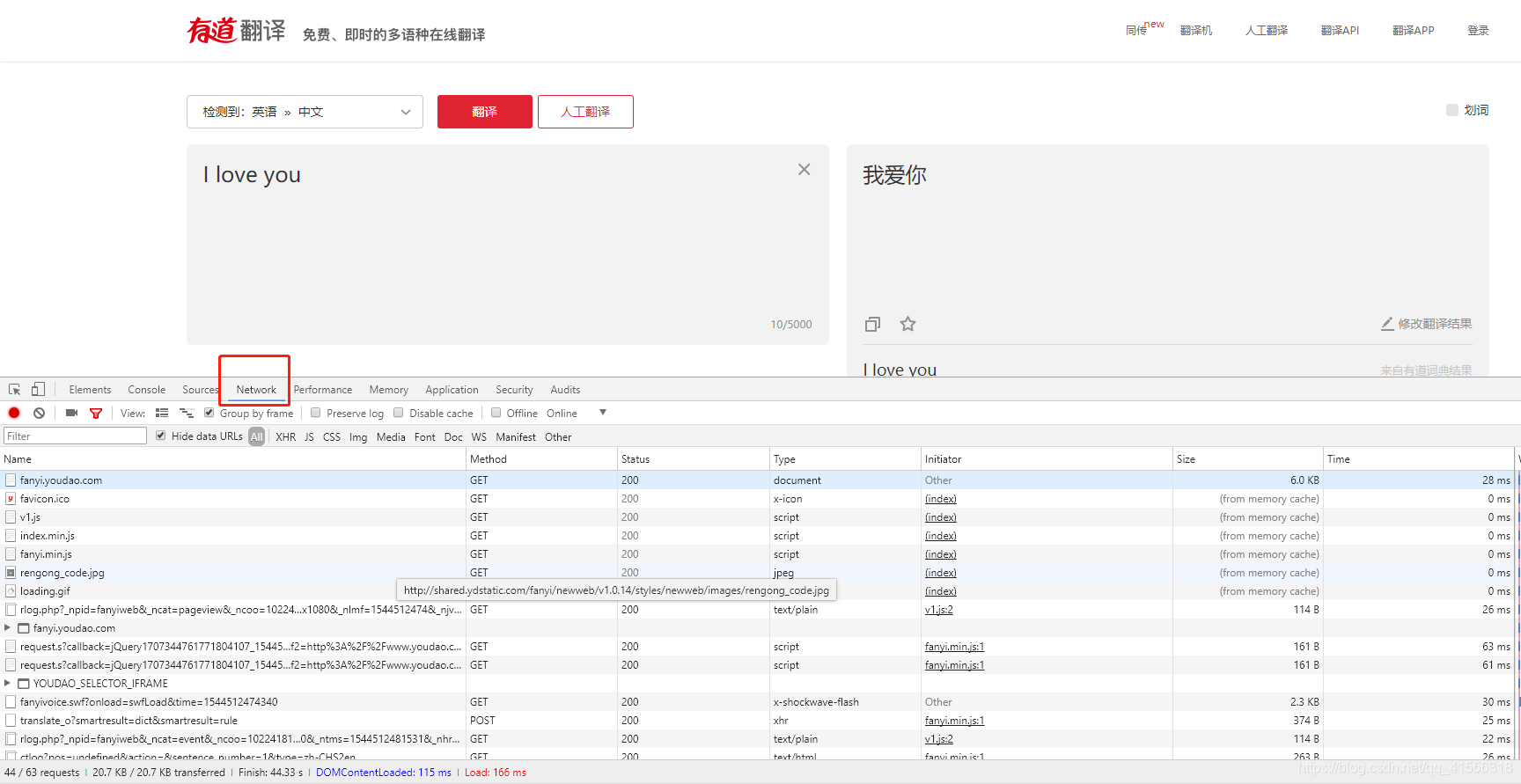 我們要看的是Network 這一塊,當我們點下自動翻譯按鈕時,在下面會看到有很多Method,其中有Get , 有Post ,這些內容都是瀏覽器與客戶端的通信內容,在客服端與服務器之間進行請求的時候,兩種最常用的方法:一種就是Get,一種就是Post,在定義上來說,Get是指從服務器請求獲得數據,而Post是向指定服務器提交被處理的數據,當然在現實情況中,Get也常常用作提交數據。但是我們這裡有Post,剛剛我們是提交數據,提交I love you!這個語句讓它翻譯,我們點進去:
我們要看的是Network 這一塊,當我們點下自動翻譯按鈕時,在下面會看到有很多Method,其中有Get , 有Post ,這些內容都是瀏覽器與客戶端的通信內容,在客服端與服務器之間進行請求的時候,兩種最常用的方法:一種就是Get,一種就是Post,在定義上來說,Get是指從服務器請求獲得數據,而Post是向指定服務器提交被處理的數據,當然在現實情況中,Get也常常用作提交數據。但是我們這裡有Post,剛剛我們是提交數據,提交I love you!這個語句讓它翻譯,我們點進去:
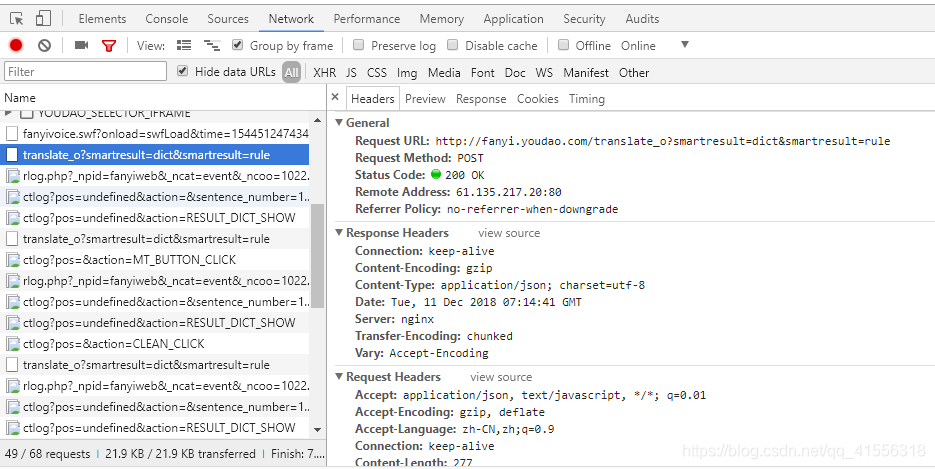 我們看到有Headers 和Preview 等,我們先看一下Preview
我們看到有Headers 和Preview 等,我們先看一下Preview
 我們看到這裡有我們所需要的結果,說明我們就找對地方了,但是在編寫程序之前,我們還是有必要講解一下Headers 中的內容:
我們看到這裡有我們所需要的結果,說明我們就找對地方了,但是在編寫程序之前,我們還是有必要講解一下Headers 中的內容:
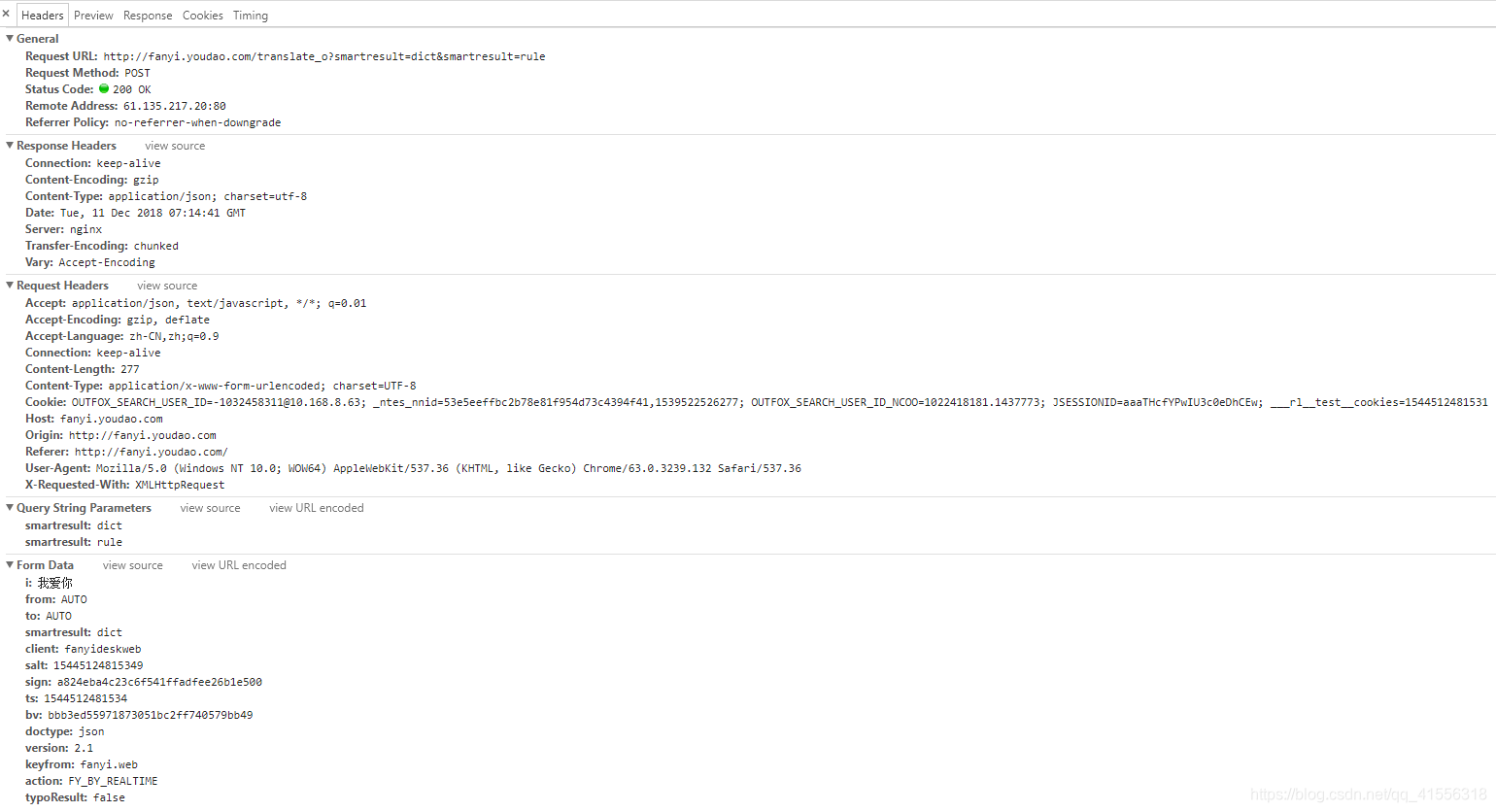 Request URL: http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule,有人會認為urlopen()函數打開的應該是 http://fanyi.youdao.com/ 這個地址,其實在內部嵌入的是前面的這個地址,你要實現翻譯的機制是在這。
Request Method: POST,請求的方法是Post的形式。
Status Code: 200 OK,狀態碼200表示正常響應。如果是404就是頁面不見了。更多關於HTTP狀態碼的信息請查閱:
Remote Address是服務器的IP地址加上打開的端口號。
Resquest Headers:是客服端(這裡就是瀏覽器,用Python代碼的時候就是我們的代碼)發送請求的Headers,這個常常用於服務端來判斷是否非人類訪問,什麼意思呢?假設我們寫一個Python代碼,然後用這個代碼批量的訪問網站的數據,這樣子,服務器的壓力就很大了,所以呢,服務器一般是不歡迎非人類的訪問的。一般我們就是使用Resquest Headers裡面的User-Agent來識別是瀏覽器訪問還是代碼訪問,大家可以看到,這裡的User-Agent顯示的系統的架構是(Windows NT 10.0; WOW64),後面你還包括瀏覽器的核心及其版本號等信息。如果你使用Python訪問的話,這個User-Agent默認就是Python URL 3.5,這樣就可能被屏蔽掉。(不過呢,如果服務器君以為這樣就可以阻擋我們前進的腳步的話,他就太天真了,這個User-Agent是可以進行自定義的,嘻嘻,後面會給大家介紹)
Form Data:其實就是我們這個Post提交的主要內容,在i這裡看到了提交的待翻譯的內容。
介紹到這裡就已經夠用了,接下來看看文檔,了解Python如何提交Post呢?
Request URL: http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule,有人會認為urlopen()函數打開的應該是 http://fanyi.youdao.com/ 這個地址,其實在內部嵌入的是前面的這個地址,你要實現翻譯的機制是在這。
Request Method: POST,請求的方法是Post的形式。
Status Code: 200 OK,狀態碼200表示正常響應。如果是404就是頁面不見了。更多關於HTTP狀態碼的信息請查閱:
Remote Address是服務器的IP地址加上打開的端口號。
Resquest Headers:是客服端(這裡就是瀏覽器,用Python代碼的時候就是我們的代碼)發送請求的Headers,這個常常用於服務端來判斷是否非人類訪問,什麼意思呢?假設我們寫一個Python代碼,然後用這個代碼批量的訪問網站的數據,這樣子,服務器的壓力就很大了,所以呢,服務器一般是不歡迎非人類的訪問的。一般我們就是使用Resquest Headers裡面的User-Agent來識別是瀏覽器訪問還是代碼訪問,大家可以看到,這裡的User-Agent顯示的系統的架構是(Windows NT 10.0; WOW64),後面你還包括瀏覽器的核心及其版本號等信息。如果你使用Python訪問的話,這個User-Agent默認就是Python URL 3.5,這樣就可能被屏蔽掉。(不過呢,如果服務器君以為這樣就可以阻擋我們前進的腳步的話,他就太天真了,這個User-Agent是可以進行自定義的,嘻嘻,後面會給大家介紹)
Form Data:其實就是我們這個Post提交的主要內容,在i這裡看到了提交的待翻譯的內容。
介紹到這裡就已經夠用了,接下來看看文檔,了解Python如何提交Post呢?
urllib.request.urlopen( url , data=None , [ timeout , ] * , cafile=None , capath=None , cadefault=False , context=None )
data must be a bytes object specifying additional data to be sent to the server, or Noneif no such data is needed. data may also be an iterable object and in that case Content-Length value must be specified in the headers. Currently HTTP requests are the only ones that use data ; the HTTP request will be a POST instead of a GET when the data parameter is provided.
data should be a buffer in the standard application/x-www-form-urlencoded format. The function takes a mapping or sequence of 2-tuples and returns an ASCII text string in this format. It should be encoded to bytes before being used as the data parameter.urllib.parse.urlencode()
上面藍色文字已經寫得很清楚了(這些內容來自urllib的Python文档的urllib.request部分),urlopen有一個data參數,如果這個參數被賦值,那麼它就是以POST的形式取代GET的形式,也就是說,如果data = None的話,就默認是以GET的形式。這裡還說了,data參數必須是基於application/x-www-form-urlencoded的格式,它還很貼心的告訴我們,你可以使用urllib.parse.urlencode()函數將字符串轉換為所需要的形式。
事實上,我們有了這兩段話的描述,我們就可以來寫代碼了:(命名為:translation.py)
response = urllib.request.urlopen("http://placekitten.com/500/600")
urllib.request.urlopen( url , data=None , [ timeout , ] * , cafile=None , capath=None , cadefault=False , context=None )
data must be a bytes object specifying additional data to be sent to the server, or
Noneif no such data is needed. data may also be an iterable object and in that case Content-Length value must be specified in the headers. Currently HTTP requests are the only ones that use data ; the HTTP request will be a POST instead of a GET when the data parameter is provided.
data should be a buffer in the standard application/x-www-form-urlencoded format. The function takes a mapping or sequence of 2-tuples and returns an ASCII text string in this format. It should be encoded to bytes before being used as the data parameter.
urllib.parse.urlencode()urllib的Python文档的urllib.request部分),urlopen有一個data參數,如果這個參數被賦值,那麼它就是以POST的形式取代GET的形式,也就是說,如果data = None的話,就默認是以GET的形式。這裡還說了,data參數必須是基於application/x-www-form-urlencoded的格式,它還很貼心的告訴我們,你可以使用urllib.parse.urlencode()函數將字符串轉換為所需要的形式。
測試題
0. urlopen() 方法的timeout 參數用於設置什麼?
答:timeout 參數用於設置連接的超時時間,單位是秒。
1. 如何從urlopen() 返回的對像中獲取HTTP 狀態碼?
答:
2. 在客戶端和服務器之間進行請求-響應時,最常用的是哪兩種方法?
答:GET 和POST。
3. HTTP 是基於請求-響應的模式,那是客戶端發出請求,服務端做出響應;還是服務端發出請求,客戶端做出響應呢?
答:發出請求的永遠是客戶端,做出響應的永遠是服務端。
4. User-Agent 屬性通常是記錄什麼信息?
答:普通瀏覽器會通過該內容向訪問網站提供你所使用的瀏覽器類型、操作系統、瀏覽器內核等信息的標識。
5. 如何通過urlopen() 使用POST 方法像服務端發出請求?
答:urlopen 函數有一個data 參數,如果給這個參數賦值,那麼HTTP 的請求就是使用POST 方式;如果data 的值是None,也就是默認值,那麼HTTP 的請求就是使用GET 方式。
6. 使用字符串的什麼方法將其它編碼轉換為Unicode 編碼?
答:decode。decode 的作用是將其他編碼的字符串轉換成unicode 編碼,相反,encode 的作用是將unicode 編碼轉換成其他編碼的字符串。
7. JSON 是什麼鬼?
答:JSON 是一種輕量級的數據交換格式,說白了這裡就是用字符串把Python 的數據結構封裝起來,便與存儲和使用。
動動手
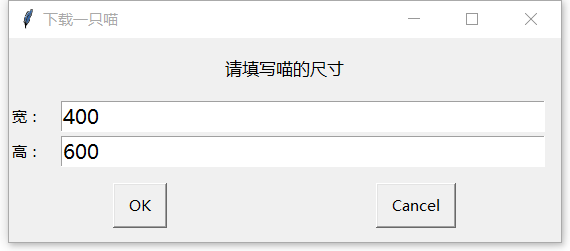
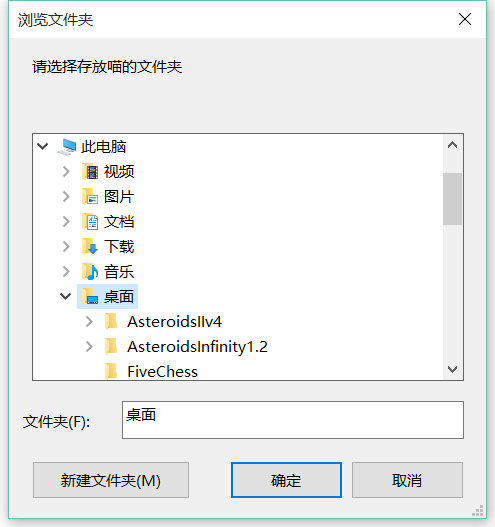
0. 配合EasyGui,給“下載一隻貓“的代碼增加互動:
- 讓用戶輸入尺寸;
- 如果用戶不輸入尺寸,那麼按默認寬400,高600下載喵;
- 讓用戶指定保存位置。
程序實現如下圖:
 代碼清單:
代碼清單:
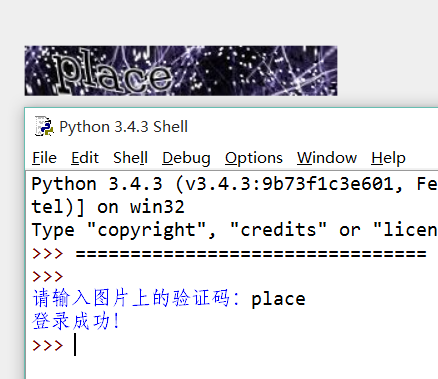
1. 寫一個登錄豆瓣的客戶端。
這道題可能要難為大家了,因為需要N 多你沒學過的知識!
不過我也不打算讓你斷送希望,下邊是一個可行的Python 2 的代碼片段,請修改為Python 3 版本。其中一些庫和知識點你可能還沒學過,但憑藉著過人的自學能力,你可以在不看答案的情況下完成任務的,對嗎?
程序實現如下圖:
 Python2 實現的代碼:
Python2 實現的代碼:
- urllib 和urllib2 合併,大多數功能放入了urllib.request 模塊;
- 原來的urllib.urlencode() 變為urllib.parse.urlencode().encode(),由於編碼的關係,你還需要在後邊加上encode('utf-8');
- cookielib 被改名為http.cookiejar;
課堂中我們還沒講,所以這裡藉機會給大家簡單科普一下cookie 是什麼東西:
我們說HTTP 協議是基於請求響應模式,就是客戶端發一個請求,服務端回復一個響應醬紫……
但HTTP 協議是無狀態的,也就是說客戶端這會兒給服務端提交了賬號密碼,服務端回複驗證通過,但下一秒客戶端說我要訪問XXOO 資源,服務端回复:“啊? ?你是誰?!”
為了解決這個尷尬的困境,有人就發明出了cookie。cookie 相當於服務端(網站)用於驗證你的身份的密文。於是客戶端每次提交請求的時候,服務端通過驗證cookie 即可知道你的身份信息。那麼正如你所猜測的,CookieJar 是Python 用於存放cookie 的對象。
當然,這裡已經給你提供了Python 2 的代碼,你不懂上邊這些,也不影響完成作業。
代碼清單:




0 留言:
發佈留言