

《零基礎入門學習Python》筆記 第057講:論一隻爬蟲的自我修養5:正則表達式
如果你在課後有勤加練習,那麼你對於字符串的查找應該是已經深惡痛絕了,你發現下載一個網頁是很容易的,但是要在網頁中查找到你需要的內容,那就是困難的,你發現字符串查找並沒有你想像的那麼簡單,並不是說直接使用find 方法找到匹配字符串的位置就可以了。
我們來舉個例子,學習了前面幾節課你應該已經嘗試過寫一個腳本來自動獲取最新的代理ip 地址,但是呢,你肯定會遇到困難,我現在來重現一下大家會遇到的困難。

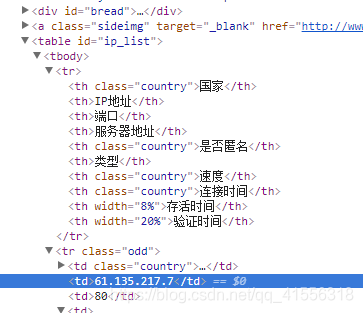 ip 為61.135.217.7 前後的標籤為td ,但是呢,別的地方也會有td,但是裡麵包括的不是ip 地址,你可能會費了九牛二虎之力,先找table,再找tbody,再找td,終於找到了ip 地址的唯一特性,找到了一個ip 地址,但是這樣寫不僅麻煩,而且不具有通用性,你在這個網站可行,在另外一個網站就不可行了,而且,萬一站長哪天心血來潮,改了一下網頁,那你更是心塞啊。
這時候你就會琢磨,可不可以按照我們需要的內容特徵來進行自動查找呢?也就是說,如果我要找一個ip 地址,那ip 地址的特徵是什麼呢?
就是由4 段數字組成,每段數字的範圍是0-255,分別是由3個點號隔開,這就是ip 地址的特徵嘛。根據這個特徵,它去網頁裡面查找。
很抱歉,字符串所附帶的方法你無法做到。
但是呢,我們遇到的問題,計算機老前輩們也早就已經想到了,並且已經幫我們設計出了非常優秀的解決方案,就是我們今天要講的正則表達式。
今天,我們將來學習使用正則表達式來匹配ip 地址。
關於正則表達式有一個非常經典的美式笑話:
ip 為61.135.217.7 前後的標籤為td ,但是呢,別的地方也會有td,但是裡麵包括的不是ip 地址,你可能會費了九牛二虎之力,先找table,再找tbody,再找td,終於找到了ip 地址的唯一特性,找到了一個ip 地址,但是這樣寫不僅麻煩,而且不具有通用性,你在這個網站可行,在另外一個網站就不可行了,而且,萬一站長哪天心血來潮,改了一下網頁,那你更是心塞啊。
這時候你就會琢磨,可不可以按照我們需要的內容特徵來進行自動查找呢?也就是說,如果我要找一個ip 地址,那ip 地址的特徵是什麼呢?
就是由4 段數字組成,每段數字的範圍是0-255,分別是由3個點號隔開,這就是ip 地址的特徵嘛。根據這個特徵,它去網頁裡面查找。
很抱歉,字符串所附帶的方法你無法做到。
但是呢,我們遇到的問題,計算機老前輩們也早就已經想到了,並且已經幫我們設計出了非常優秀的解決方案,就是我們今天要講的正則表達式。
今天,我們將來學習使用正則表達式來匹配ip 地址。
關於正則表達式有一個非常經典的美式笑話:
有些人面臨一個問題的時候會想:“我知道,可以使用正則表達式來解決這個問題。”於是,現在他就有兩個問題了。
沒錯,正則表達式的確是很難學,但卻非常有用。在編寫字符串網頁或程序的時候,經常會有查找某些符合複雜規則字符串的需求,例如,我們需要查找的ip 地址的規則。那麼,使用 Pythob 自帶的字符串方法,你一定會惱羞成怒,那麼這時候,如果你懂得正則表達式,你會發現,這真是靈丹妙藥啊。
因為正則表達式就是為了描述這些複雜規則的工具。正則表達式本身就是用於描述這些規則的。不同的語言均有使用正則表達式的方法,但各不相同,Python 是使用re 模塊來實現的,因為這一部分比較難,所以我們邊舉例子邊講解。
有些人面臨一個問題的時候會想:“我知道,可以使用正則表達式來解決這個問題。”於是,現在他就有兩個問題了。
re.search方法
re.search 掃描整個字符串並返回正則表達式模式第一次成功匹配的位置。
函數語法:
函數語法:
re.search(pattern, string, flags=0)
函數參數說明:
參數 描述 pattern 匹配的正則表達式 string 要匹配的字符串。 flags 標誌位,用於控制正則表達式的匹配方式,如:是否區分大小寫,多行匹配等等。
匹配成功re.search方法返回一個匹配的對象,否則返回None。
有人就會認為,你說了這麼多,和find() 方法也沒有什麼區別啊,使用find() 方法也可以實現上面的功能啊。如下:
函數參數說明:
| 參數 | 描述 |
|---|---|
| pattern | 匹配的正則表達式 |
| string | 要匹配的字符串。 |
| flags | 標誌位,用於控制正則表達式的匹配方式,如:是否區分大小寫,多行匹配等等。 |
匹配成功re.search方法返回一個匹配的對象,否則返回None。




0 留言:
發佈留言