

《零基礎入門學習Python》筆記 第055講:論一隻爬蟲的自我修養3:隱藏
目錄
0. 請寫下這一節課你學習到的內容:格式不限,回憶並複述是加強記憶的好方式!
測試題
0. 服務器是如何識訪問來自瀏覽器還是非瀏覽器的?
1. 明明代碼跟視頻中的栗子一樣,一運行卻出錯了,但在不修改代碼的情況下再次嘗試運行卻又變好了,這是為什麼呢?
2. Request 是由客戶端發出還是由服務端發出?
3. 請問如何為一個Request 對象動態的添加headers?
4. 簡單來說,代理服務器是如何工作的?他有時為何不工作了?
5. HTTP 有好幾種方法(GET,POST,PUT,HEAD,DELETE,OPTIONS,CONNECT),請問你如何曉得Python 是使用哪種方法訪問服務器呢?
6. 上一節課後題中有涉及到登陸問題,辣麼,你還記得服務器是通過什麼來確定你是登陸還是沒登陸的麼?他會持續到什麼時候呢?
動動手
0. 編寫一個爬蟲,爬百度百科“網絡爬蟲”的詞條
1. 直接打印詞條名和鏈接不算什麼真本事兒,這題要求你的爬蟲允許用戶輸入搜索的關鍵詞。
2. 嘩啦啦地丟一堆鏈接給用戶可不是什麼好的體驗,我們應該先打印10 個鏈接,然後問下用戶“您還往下看嗎?
0. 請寫下這一節課你學習到的內容:格式不限,回憶並複述是加強記憶的好方式!
上節課我們說過了,有一些網站比較痛恨爬蟲程序,它們不喜歡被程序所訪問,所以它們會檢查鏈接的來源,如果說來源不是正常的途徑,那麼它就會把你給屏蔽掉,所以呢,要讓我們的程序可以持續的干活,要可以投入生產,我們就需要對代碼進行隱藏,讓它看起來更像是普通人瀏覽器的正常點擊。
我們知道,服務器檢查鏈接是通過檢查鏈接中的Headers 中的User Agent 來判斷你是來自於代碼還是來自於瀏覽器,像我們的Python,你用Python默認的Headers 中的User Agent 是Python 加上版本號,服務器一檢查是Python,就會把你屏蔽掉。我們可以修改Headers 來模擬正常的瀏覽器訪問。
先看一下文檔:
 urllib.request. Request有一個headers的參數,通過修改headers參數,你可以設置自己的headers,這個參數是一個字典,你可以通過兩種途徑來設置:一種是你直接設置一個字典,然後作為參數傳給Request,或者第二種,在Request生成之後,調用add_header()將其加進去。我們使用上節課的例子來嘗試一下:
第一種代碼清單:
urllib.request. Request有一個headers的參數,通過修改headers參數,你可以設置自己的headers,這個參數是一個字典,你可以通過兩種途徑來設置:一種是你直接設置一個字典,然後作為參數傳給Request,或者第二種,在Request生成之後,調用add_header()將其加進去。我們使用上節課的例子來嘗試一下:
第一種代碼清單:
- 通過Request 的headers 參數修改
- 通過Request.add_header() 方法修改
修改User-Agent 可以算是最簡單的隱藏方法了,也是切實可行的,不過呢,如果是用Python 抓取網頁,例如批量下載圖片,你一個IP 地址短時間內連續的進行訪問,那麼這是不符合正常人類的標準的,而且對服務器帶來的壓力不小,所以服務器合情合理會把你屏蔽掉,屏蔽的做法也很簡單,只需要記錄每個IP的訪問頻率,在單位時間內,如果訪問頻率超過一個閾值,那麼服務器就會認為這個IP很有可能是一個爬蟲,那麼服務器就會把不管它的User-Agent是什麼了,服務器就會返回一個驗證碼的界面,因為用戶會填寫驗證碼,但是爬蟲不會,這就會合理的把你的訪問給屏蔽掉。
就我們目前的學習水平來說,有兩種做法可以解決這種問題,一種就是延遲提交的時間,讓我們的爬蟲看起來更像是一個正常的人類在瀏覽(這是沒有辦法的辦法) ;還有一種就是使用代理。
首先說第一種方法,我們可以使用time模塊來完成延遲操作:(這種方法的工作效率太慢了)
嘿,兄弟,哥們儿訪問這個網址有點困難,幫忙解決一下唄!
然後你就把需要訪問的網址告訴代理先生,代理幫你訪問,然後把他看到的所有內容原封不動的轉發給你。
這就是代理。
代理的工作原理就是這麼簡單,因此呢,服務器看到的IP地址就是代理的IP地址,而不是你的IP地址,這樣子你用很多個代理同時發起訪問,服務器也沒有辦法。使用代理的步驟如下:
- 1.參數是一個字典{'類型' :'代理ip: 端口號'}
proxy_support = urllib.request.ProxyHandler({})
它這個參數就是一個字典,字典的鍵就是代理的類型(如:http,https...),值就是對應的ip 或者域名+端口號
- 2.定制、創建一個opener
(opener可以看做是私人訂製,當你使用urlopen 打開一個普通網頁的時候,你就是在使用默認的opener 來工作,而這個opener 是可以有我們定制的,例如我們可以給它加上特殊的headers,或者指定代理,我們使用下面的語句定制、創建一個opener)
opener = urllib.request.build_opener(proxy_support)
- 3a.安裝opener
我們使用urllib.request.install_opener(opener),把它安裝到系統中,這是一勞永逸的做法,因為在此之後,你只要使用普通的urlopen() 函數,就是使用定制好的opener 進行工作,如果你不想替換掉默認的opener,你可以使用下面的語句調用opener。
- 3b.調用opener
opener.open(url)
我們來舉個例子:
我們需要代理ip,直接在網上搜索即可。
嘿,兄弟,哥們儿訪問這個網址有點困難,幫忙解決一下唄!
然後你就把需要訪問的網址告訴代理先生,代理幫你訪問,然後把他看到的所有內容原封不動的轉發給你。
這就是代理。
測試題
0. 服務器是如何識訪問來自瀏覽器還是非瀏覽器的?
答:通過發送的HTTP 頭中的User-Agent 來進行識別瀏覽器與非瀏覽器,服務器還以User-Agent 來區分各個瀏覽器。
1. 明明代碼跟視頻中的栗子一樣,一運行卻出錯了,但在不修改代碼的情況下再次嘗試運行卻又變好了,這是為什麼呢?
答: 在網絡信息的傳輸中會出現偶然的“丟包”現象,有可能是你發送的請求服務器沒收到,也有可能是服務器響應的信息不能完整送回來……尤其在網絡阻塞的時候。所以,在設計一個“稱職”的爬蟲時,需要考慮到這偶爾的“丟包”現象。
2. Request 是由客戶端發出還是由服務端發出?
答:我們之前說HTTP 是基於“請求-響應”模式,Request 即請求的意思,而Response 則是響應的意思。由客戶端首先發出Request,服務器收到後返回Response。
3. 請問如何為一個Request 對象動態的添加headers?
答:add_header() 方法往Request 對象添加headers。
4. 簡單來說,代理服務器是如何工作的?他有時為何不工作了?
答: 將信息傳給代理服務器,代理服務器替你向你要訪問的服務器發送請求,然後在將服務器返回的內容返回給你。
因為有“丟包”現象發生,所以多了一個中間人就意味著會多一層發生“丟包”的機率,且大多數代理並不只為一個人服務,尤其是免費代理。
PS:大家想做“壞壞”的事情時可以考慮多幾層代理,一般來說路由器日誌並不會保存很長時間,幾層代理後,基本很難查到是誰請求的。
5. HTTP 有好幾種方法(GET,POST,PUT,HEAD,DELETE,OPTIONS,CONNECT),請問你如何曉得Python 是使用哪種方法訪問服務器呢?
答:使用get_method() 方法獲取Request 對象具體使用哪種方法訪問服務器。最常用的無非就是GET 和POST 了,當Request 的data 參數被賦值的時候,get_method() 返回'POST',否則一般情況下返回'GET'。
6. 上一節課後題中有涉及到登陸問題,辣麼,你還記得服務器是通過什麼來確定你是登陸還是沒登陸的麼?他會持續到什麼時候呢?
答: 是cookie,服務器通過判斷你提交的cookie 來確定訪問是否來自”熟人“。
簡單來說cookie 可以分成兩類:
- 一類是即時過期的cookies,稱為“會話” cookies,當瀏覽器關閉時(這裡是python 的請求程序)自動清除
- 另一類是有期限的cookies,由瀏覽器進行存儲,並在下一次請求該網站時自動附帶(如果沒過期或清理的話)
動動手
小甲魚打算在這裡先給大家介紹一個壓箱底的模塊—— Beautiful Soup 4
翻譯過來名字有點詭異:漂亮的湯?美味的雞湯?呃……
好吧,只要你寫出一個普羅大眾都喜歡的模塊,你管它叫“Beautiful Shit”大家也是能接受的…… Beautiful Soup 是一個可以從HTML 或XML 文件中提取數據的Python 庫。它能夠通過你喜歡的轉換器實現慣用的文檔導航,查找,修改文檔的方式。Beautiful Soup 會幫你節省數小時甚至數天的工作時間。
這玩意兒到底怎麼用?
看這-> 傳送門
上邊鏈接是官方的快速入門教程(不用懼怕,這次有中文版了),請大家花差不多半個小時的時間自學一下,然後完成下邊題目。
噢,對了,大家可以使用pip 安裝(Python3.4 以上自帶的神一般的軟件包管理系統,有了它Python 的模塊安裝、卸載全部一鍵搞定!)
打開命令行窗口(CMD) -> 輸入pip install BeautifulSoup4 命令) -> 搞定。
Beautiful Soup 是一個可以從HTML 或XML 文件中提取數據的Python 庫。它能夠通過你喜歡的轉換器實現慣用的文檔導航,查找,修改文檔的方式。Beautiful Soup 會幫你節省數小時甚至數天的工作時間。
這玩意兒到底怎麼用?
看這-> 傳送門
上邊鏈接是官方的快速入門教程(不用懼怕,這次有中文版了),請大家花差不多半個小時的時間自學一下,然後完成下邊題目。
噢,對了,大家可以使用pip 安裝(Python3.4 以上自帶的神一般的軟件包管理系統,有了它Python 的模塊安裝、卸載全部一鍵搞定!)
打開命令行窗口(CMD) -> 輸入pip install BeautifulSoup4 命令) -> 搞定。
0. 編寫一個爬蟲,爬百度百科“網絡爬蟲”的詞條
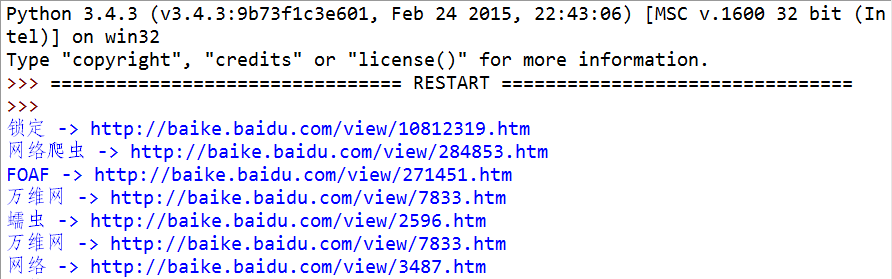 提示:題目中需要使用到簡單的正則表達式(在官方的快速入門教程有演示),如果你希望馬上就深入學習正則表達式,當然可以給你預支一下後邊的知識-> Python3如何優雅地使用正則表達式
代碼清單:
提示:題目中需要使用到簡單的正則表達式(在官方的快速入門教程有演示),如果你希望馬上就深入學習正則表達式,當然可以給你預支一下後邊的知識-> Python3如何優雅地使用正則表達式
代碼清單:
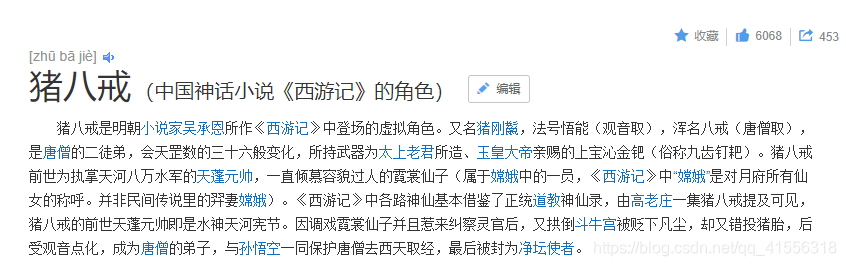
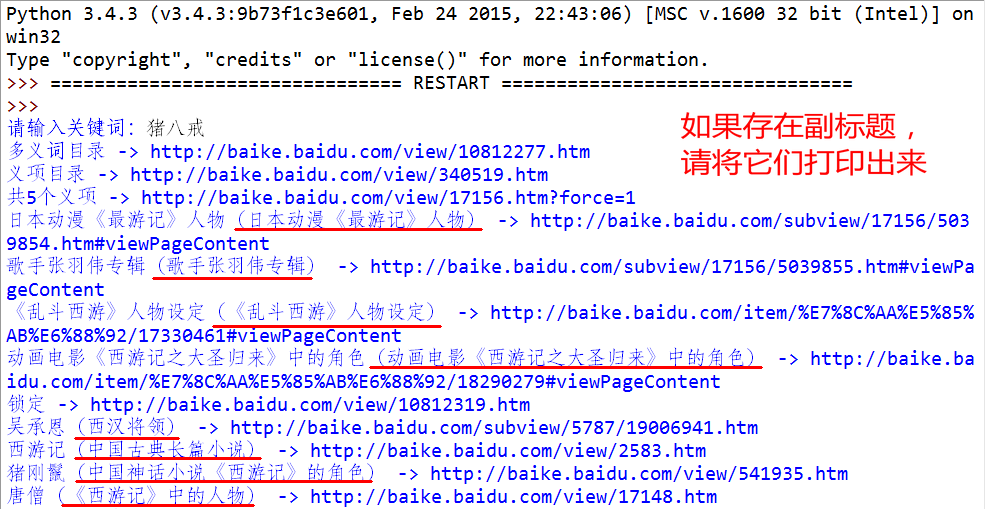
1. 直接打印詞條名和鏈接不算什麼真本事兒,這題要求你的爬蟲允許用戶輸入搜索的關鍵詞。
然後爬蟲進入每一個詞條,然後檢測該詞條是否具有副標題(比如搜索“豬八戒”,副標題就是“(中國神話小說《西遊記》的角色)”),如果有,請將副標題一併打印出來:
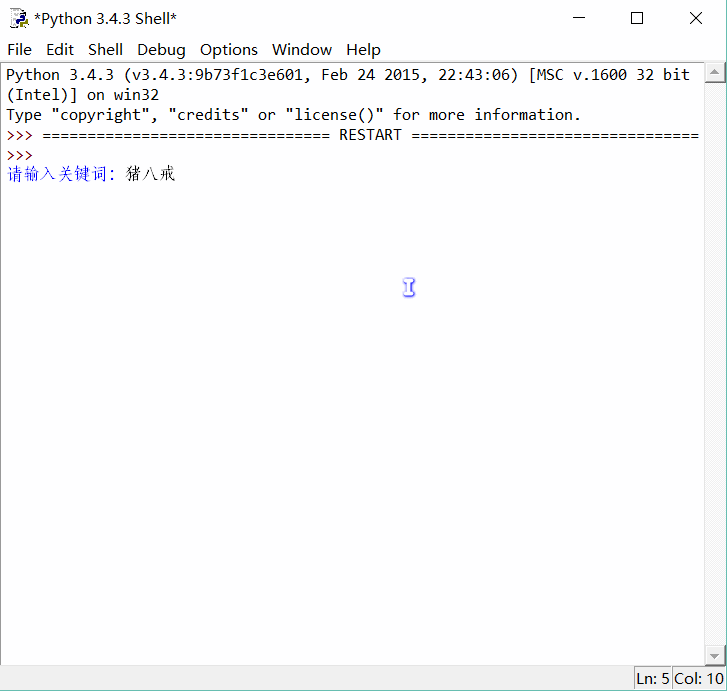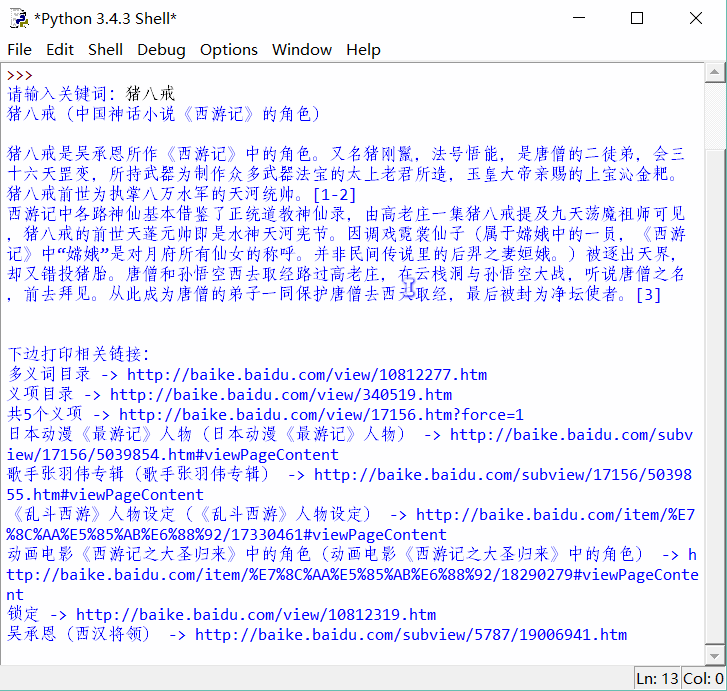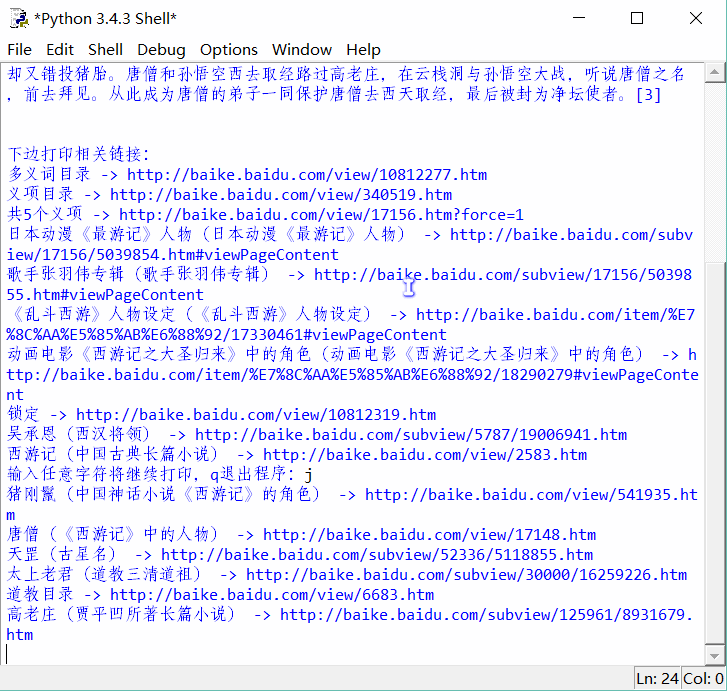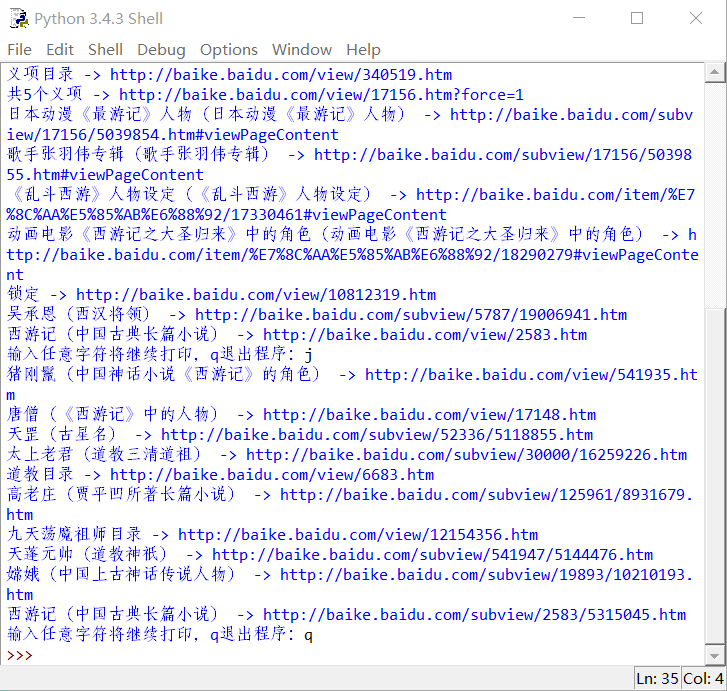
 程序實現效果如下:
程序實現效果如下:
 代碼清單:
代碼清單:
2. 嘩啦啦地丟一堆鏈接給用戶可不是什麼好的體驗,我們應該先打印10 個鏈接,然後問下用戶“您還往下看嗎?
來,我給大家演示下:
 然後為了增加用戶體驗,代碼需要捕獲未收錄的詞條,並提示:
然後為了增加用戶體驗,代碼需要捕獲未收錄的詞條,並提示:
 代碼清單:
代碼清單:




0 留言:
發佈留言