《零基礎入門學習Python》筆記 第056講:論一隻爬蟲的自我修養4:網絡爬圖
今天我們結合前面學習的知識,進行一個實例,從網絡上下載圖片,話說我們平時閒來無事會上煎蛋網看看新鮮事,那麼,熟悉煎蛋網的朋友一定知道,這裡有一個隨手拍的欄目,我們今天就來寫一個爬蟲,自動抓取每天更新的隨手拍。
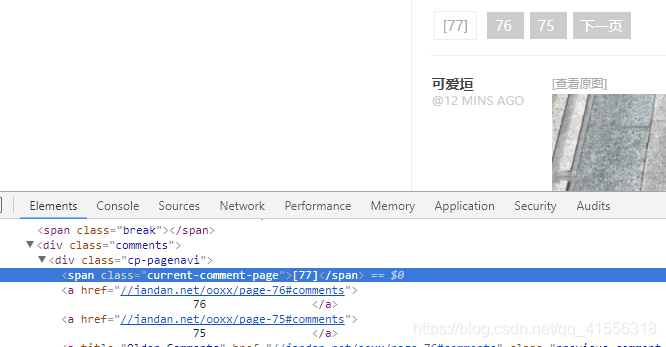
1.那我們怎樣獲取目前最大的頁碼數呢(最新頁碼),我們在頁碼[77]這個位置點擊右鍵,審查元素,看到了:<span class="current-comment-page">[77]< /span>
我們完全可以通過搜索 current-comment-page 在後面偏移3位就可以得到77這個最新的頁面,因為你不能去輸入一個具體的數字,因為這裡的數字每天都會改變。
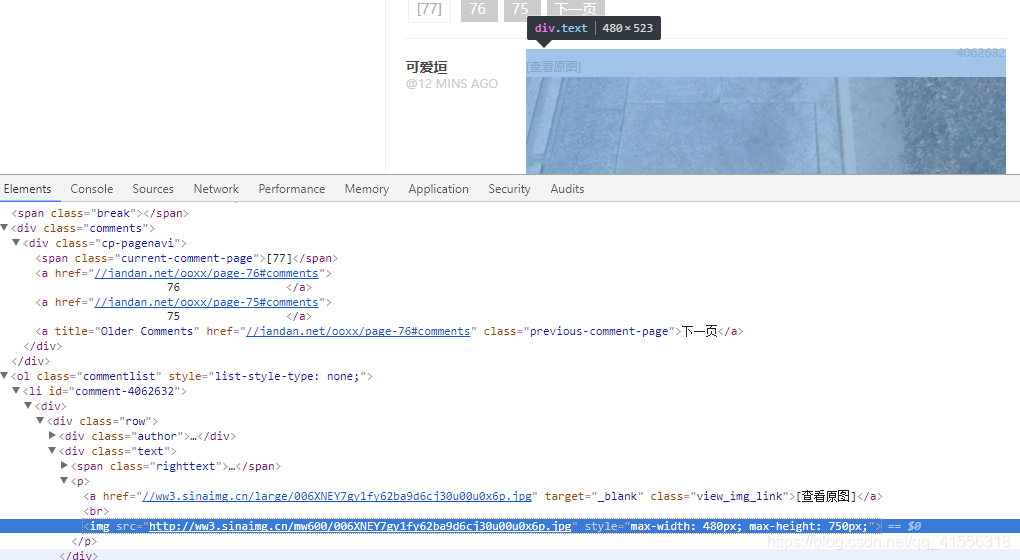
2.我們在圖片的位置點擊右鍵,審查元素,發現了圖片的地址,都是來自於新浪,然後都在img 標籤裡,我們就可以使用img src 作為關鍵詞來進行查找,搜索到了圖片的地址就可以參照我們之前下載一隻貓的例子了。把下面圖片的地址用urlopen() 打開,然後將其save 到一個文件裡去(二進制),就可以了。
<img src="http://ww3.sinaimg.cn/mw600/006XNEY7gy1fy62ba9d6cj30u00u0x6p.jpg" style="max-width: 480px; max-height: 750px;">
我們弄清楚了以上幾點,就可以開始寫我們的爬蟲程序啦.....
(我們抓取前10頁的圖片,保存到指定的本地文件夾中)
下面是老師講的代碼:
-
-
-
-
-
-
-
req = urllib.request.Request(url)
-
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.65 Safari/537.36')
-
-
-
-
-
-
-
-
-
-
response = urllib.request.urlopen(url)
-
-
-
-
-
-
html = html.decode('utf-8')
-
-
-
a = html.find( 'current-comment-page') + 23
-
-
-
-
-
-
html = url_open(url).decode('utf-8')
-
-
-
-
a = html.find('img src=')
-
-
b = html.find('.jpg', a, a+255)
-
-
-
img_addrs.append(html[a+9: b+4])
-
-
-
-
a = html.find('img src=', b)
-
-
-
-
def save_imgs(folder, img_addrs):
-
-
filename = each.split('/')[-1]
-
with open(filename, 'wb') as f:
-
-
-
-
-
def download_figures(folder = 'figures', page = 10):
-
-
-
-
url = "http://jandan.net/ooxx/"
-
page_num = int(get_page(url))
-
-
-
page_url = url + 'page-' + str(page_num) + '#comments'
-
-
img_addrs = find_imgs(page_url)
-
save_imgs(folder, img_addrs)
-
-
-
if __name__ == '__main__':
-
但是現在,煎蛋網用這段代碼是無法實現的了,主要問題在於沒有辦法爬取到.jpg,這是因為這個網站已經被加密了。
怎樣判斷一個網站被加密了,就是
使用urllib.urlopen導出html文本和審查元素中相應字段對不上。
以後你會發現對不上是常態,一般是JS加密的 可以說大一點的網站這些信息都會對不上。
那怎麼解決呢?
目前我只用的一種方法就是:使用selenium爬取js加密的網頁
所以呢,我的代碼就是下面這樣子了:
-
-
-
from selenium import webdriver
-
-
-
-
req = urllib.request.Request(url)
-
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36')
-
response = urllib.request.urlopen(url)
-
-
-
-
-
chrome = webdriver.Chrome()
-
-
html = chrome.page_source
-
-
-
-
def get_page(url): #得到最新页面的页码数(可以使用不加密读码得到,为了加快速度)
-
-
-
#然后就是查找 html 中的 'current-comment-page'
-
a = html.find( 'current-comment-page') + 23 #加上 23 位偏移就刚到到页码数的第一位数字
-
b = html.find(']', a) #找到 a 位置之后的第一个方括号所在位置的索引坐标
-
-
return html[a : b] #这就是最新的页码数啦
-
-
-
-
html = html.decode('utf-8')
-
-
-
a = html.find( 'current-comment-page') + 23
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
b = html.rfind('img src=', a-100, a)
-
-
-
-
img_addrs.append(html[b+9: a+4])
-
-
a = html.find('.jpg', a+4)
-
-
-
-
-
-
def save_imgs(folder, img_addrs):
-
-
filename = each.split('/')[-1]
-
with open(filename, 'wb') as f:
-
-
-
-
def download_figures(folder = 'figures', page = 2):
-
-
-
-
url = "http://jandan.net/ooxx/"
-
page_num = int(get_page(url))
-
-
-
-
page_url = url + 'page-' + str(page_num) + '#comments'
-
-
img_addrs = find_imgs(page_url)
-
save_imgs(folder, img_addrs)
-
-
-
if __name__ == '__main__':
-
完美實現目標,只不過selenium 的速度是真的慢,以後如果有更好的辦法,會繼續改進的,也希望大家多多批評指導。






0 留言:
發佈留言